
The Big Data bust of the 1500s: lessons from the first scientific data miner
11 May 2015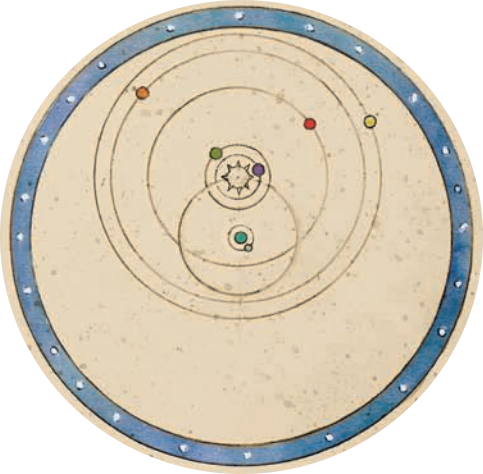
The Big Data craze is in full swing within many scientific fields, especially neuroscience. Since we can’t hope to understand the tangled web of the brain by looking at only one tiny piece, groups have started to amass huge datasets describing brain function and connections. The idea is that, if we can get enough careful measurements all together, then we can have computers search for patterns that explain as much of the data as possible.
This approach would have made perfect sense to Tycho Brahe, a Danish astronomer born in 1546. Although people have been studying the skies since the dawn of civilization, Brahe was the first to make a detailed catalog of stellar and planetary positions.
Scientific American’s description of his research program makes it clear that this was one of the first Big Data science projects:
Brahe was a towering figure. He ran a huge research program with a castlelike observatory, a NASA-like budget, and the finest instruments and best assistants money could buy. […] Harvard University historian Owen Gingerich often illustrates Brahe’s importance with a mid-17th-century compilation by Albert Curtius of all astronomical data gathered since antiquity: the great bulk of two millennia’s worth of data came from Brahe.
Brahe then announced a model of planetary motion that fit his vast dataset exactly. You could use it to predict precisely where the stars and planets would be in the sky tomorrow. It relied on a fancy prosthaphaeresis algorithm that allowed for the computation of a massive number of multiplications. The only problem was that it was deeply, fundamentally wrong.
It was called the Geoheliocentric Model, since it proposed that the sun orbited the stationary Earth and the other planets orbited the sun. It was attractive on philosophical, scientific, and intuitive grounds (of course the Earth isn’t moving, what could possibly power such a fast motion of such a heavy object?). And it illustrates a critical problem with the data-mining approach to science: just because you have a model that predicts a pattern doesn’t mean that the model corresponds to reality.
What might be needed is not just more data, or more precise data, but new hypotheses that drive the collection of entirely different types of data. It doesn’t mean that Big Data isn’t going to be part of the solution (most neuroimaging datasets have been laughably small so far), but simply performing pattern recognition on larger and larger datasets doesn’t guarantee that we’re getting closer to the truth. The geoheliocentric model was eventually brought down not with bigger datasets, but by a targeted experiment looking at small annual patterns of stellar motion.
Interestingly, there is a clear counterexample to my argument in the work of Dan Yamins, a postdoc with Jim DiCarlo. Dan has shown that a neural network model that learns to label objects in a large set of images ends up looking a lot like the visual processing regions of the brain (in terms of its functional properties). This is surprising, since you could imagine that there might be lots of other ways to understand images.
I wonder if this works because the brain is itself a Big Data mining machine, trained up through childhood to build models of our experiences. Then finding the strongest patterns in big datasets of experiences (images, videos, audio) might come up with the same solution as the brain. Or maybe our neural network models are starting to approximate the broad functional properties of the brain, which makes them a good hypothesis-driven model for finding patterns (rather than just blind data mining). As John Wixted stressed at the CEMS conference last week, hypothesis-free data anlysis has a seductive purity, but the true value of datasets (regardless of their size) comes only through the lens of carefully constructred ideas.
Comments? Complaints? Contact me @ChrisBaldassano