Back in Spring 2015, when I had just started as a postdoc at Princeton, Janice Chen was wrestling with a data analysis problem in a new kind of dataset she had collected. She had fMRI data from subjects watching an hour-long movie and then freely recalling (over tens of minutes) the narrative. She wanted to see whether people’s brains during recall looked like they were replaying activity patterns during movie-watching - was it be possible to track which part of the movie people were thinking about during each moment of recall? I was absolutely captivated by this experiment, which broke all the rules about how you were supposed to collected fMRI data, especially since people were talking while being scanned (which conventional wisdom said should ruin your data). So I volunteered to help with analysis, which started as a side project and eventually turned into the main focus of my years at Princeton.
What we came up with was a Hidden Markov Model (HMM), which models brain activity while experiencing or remembering a story as proceeding through an ordered sequence of states, each corresponding to some event in the story. It turned out that in addition to movie-recall alignment, this model could do a bunch of other things as well, such as figuring out how to divide a story into events or detect anticipation of upcoming events in the story, and along with the paper describing the results we also released a python code for the HMM as part of the brainIAK toolbox. My lab and others have continued finding uses for this model, like this recent super-exciting preprint from James Antony.
My blog (when I remember to actually post things) usually is intended to give non-technical explanations of research, but in this post I’m going to get deeper into a) how the HMM finds event boundaries, and b) a recent update I made to the brainIAK code that improves how this fitting process works.
How the HMM fits data
Let’s look at a tiny simulated dataset, with 10 voxels and 20 timepoints:
You can see visually where the event boundaries are - these are the timepoints (7 to 8, and 16 to 17) where the spatial pattern of activity across voxels suddenly shifts to a new stable pattern.
The HMM is using a probabilistic model to try to estimate a) what the patterns for each event look like, and b) which event each timepoint belongs to. This is a chicken-and-egg problem, since it is hard to cluster timepoints into events without knowing what they look like (and the boundaries between events are usually much less obvious in real datasets than in this toy example). The way the HMM gets started is by using its prior estimate of where events are likely to be. Let’s plot these prior probabilities as black lines, on top of the data:
The HMM is certain that the first timepoint is in the first event and the last timepoint is in the last event, and the timepoints around in the middle are most likely to be in the second event. This prior distribution comes from summing over all possible sets of event boundaries - if we wrote down every possible way of slicing up these 20 timepoints into 3 events, timepoint 10 would be in the second event about in about half of these.
Now that we have this initial guess of which events belong to each timepoint, we can make a guess about what each event’s pattern looks like. We can then use these patterns to make a better assignment of timepoints to events, and keep alternating until our guesses aren’t getting any better. Here is an animation showing this fitting procedure, with the event probability estimates on the top and the event voxel pattern estimates on the bottom:
We can see that the HMM can perfectly find the true boundaries, shifting the prior distributions to line up with the underlying data. Note that the HMM doesn’t explicitly try to find “event boundaries,” it just tries to figure out which event each timepoint is in, but we can pull out event boundaries from the solution by looking for where the event label switches.
How to confuse the (original) HMM
This original HMM has been shown empirically to work well on a number of different datasets, as mentioned above. The fitting procedure, however, isn’t guaranteed find the best solution. One thing the original HMM has trouble with is if the true event lengths are very far from the prior, with some events much smaller than others. For example, here is another simulated dataset:
Here the first event is very long, which means that starting with the prior as our initial guess is not great. The HMM thinks that timepoint 13, for example, is much more likely to be in event 2 or 3 instead of event 1. When we start with this initial guess and run the fitting, here’s what happens:
The HMM correctly figured out that there is an event boundary between timepoints 13 and 14, but missed the other transition between 16 and 17. The problem is the event patterns for events 1 and 2 accidentally latch onto the same event, forcing event pattern 3 to cover the last two events. Once this starts happening, the model has no way to recover and re-allocate its event patterns. How can we give the HMM a way to escape from its bad decisions?
Split-Merge HMM to the rescue
In the new version of brainIAK, I’ve now added a split_merge option to the EventSegment class. If enabled, this forces the HMM to try reallocating its events at every step of fitting, by finding a) neighboring pairs of events with very similar patterns, indicating that they should be merged, and b) events that could be split in half into two very different-looking events. It checks to see if it can find a better solution by simultaneously merging one of the pairs of (a) and splitting one of the events from (b), to keep the same number of events overall. The number of different combinations the HMM tries is controlled by a split_merge_proposals parameter (defaults to 1).
This will come at a cost of extra computational time (which will increase even more with more split_merge_proposals) - does this extra flexibility lead to better solutions? Let’s try fitting the simulated data with very uneven events again:
Near the end of fitting the HMM realizes that the first two events can be merged, freeing up an extra event to split the final six timepoints into two separate events, as they should be. You can also see the event patterns for events 2 and 3 jump rapidly when it performs this split-merge.
Testing on real data
This proof-of-concept shows that using split-merge can help on toy datasets, but does it make a difference on real fMRI data? I don’t have a conclusive answer to this question - if you are interested, try it out and let me know!
I did try applying both HMM variants to some real fMRI data from the brainIAK tutorial. This is group-average data from 17 subjects watching the 50 minutes of Sherlock, downsampled into 141 coarse regions of interest. Fitting the original and split-merge HMMs using 60 events and then comparing to human-annotated boundaries, the original HMM is able to find 18 out of 53 boundaries (p=0.01 by permutation test), while the split-merge HMM is able to find 21 (p=0.002). Using split-merge seems to help a bit at the beginning of the show, where observers label many short events close together. Here is a plot of the first 12 minutes of the data, comparing the HMM boundaries to the human-annotated ones:
Both of the HMM variants are doing a decent job finding human-annotated boundaries, but the split-merge HMM is able to find some extra event boundaries (black boxes) that are perhaps too small for the original HMM to find.
More extensive testing will need to be done to understand the kinds of data for which this can help improve fits, but if you are willing to spend a little more time fitting HMMs then give split-merge a try!
Code to produce the figures in this post:
#%% Imports
frombrainiak.eventseg.eventimportEventSegmentimportmatplotlib.pyplotaspltfrommatplotlib.animationimportFuncAnimationimportmatplotlib.patchesaspatchesimportdeepdishasddimportnumpyasnpfromscipyimportstatsdefgenerate_data(event_labels,noise_sigma=0.1):n_events=np.max(event_labels)+1n_voxels=10event_patterns=np.random.rand(n_events,10)data=np.zeros((len(event_labels),n_voxels))fortinrange(len(event_labels)):data[t,:]=event_patterns[event_labels[t],:]+\
noise_sigma*np.random.rand(n_voxels)returndatadefplot_data(data,prob=None,event_patterns=None,create_fig=True):ifcreate_fig:ifevent_patternsisnotNone:plt.figure(figsize=(6,6))else:plt.figure(figsize=(6,3))ifevent_patternsisnotNone:plt.subplot(2,1,1)data_z=stats.zscore(data.T,axis=0)plt.imshow(data_z,origin='lower')plt.xlabel('Time')plt.ylabel('Voxels')plt.xticks(np.arange(0,19,5))plt.yticks([])ifprobisnotNone:plt.plot(9.5*prob/np.max(prob),color='k')ifevent_patternsisnotNone:plt.subplot(2,1,2)plt.imshow(stats.zscore(event_patterns,axis=0),origin='lower')plt.xlabel('Events')plt.ylabel('Voxels')n_ev=event_patterns.shape[1]plt.xticks(np.arange(0,n_ev),[str(i)foriinrange(1,n_ev+1)])plt.yticks([])plt.clim(data_z.min(),data_z.max())defanimate_fit(f,fname):plt.figure(figsize=(6,6))frames=np.unique(np.round(np.logspace(0,2.5,num=20)))anim=FuncAnimation(plt.gcf(),f,frames=frames,interval=300)anim.save(fname,dpi=80,writer='imagemagick')defhuman_match(bounds,human_bounds,nTR,nPerm=1000,threshold=3):event_counts=np.diff(np.concatenate(([0],bounds,[nTR])))perm_bounds=boundsmatch=np.zeros(nPerm+1)forpinrange(nPerm+1):forhbinhuman_bounds:ifnp.any(np.abs(perm_bounds-hb)<=threshold):match[p]+=1perm_counts=np.random.permutation(event_counts)perm_bounds=np.cumsum(perm_counts)[:-1]returnmatch[0],np.mean(match>=match[0])deffit(t):plt.clf()es=EventSegment(3,n_iter=t)es.fit(data)plot_data(data,es.segments_[0],es.event_pat_,create_fig=False)deffit_split_merge(t):plt.clf()es=EventSegment(3,n_iter=t,split_merge=True)es.fit(data)plot_data(data,es.segments_[0],es.event_pat_,create_fig=False)defplot_bounds(bounds,n):w=1forbinbounds:plt.gca().add_patch(patches.Rectangle((b-w/2,n),2,1,color='C%d'%n))#%% Simulation #1
event_labels=np.array([0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,2,2,2])np.random.seed(0)data=generate_data(event_labels)plot_data(data)plt.show()#%% Plot prior
es_prior=EventSegment(3)prior=es_prior.model_prior(len(event_labels))[0]plot_data(data,prior)plt.text(1.5,8.8,'Event 1')plt.text(8.2,4.3,'Event 2')plt.text(15.5,8.8,'Event 3')plt.show()#%% Fitting simulation #1
animate_fit(fit,'fit.gif')#%% Simulation #2
event_labels=np.array([0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,2,2,2])np.random.seed(0)data=generate_data(event_labels)es_prior=EventSegment(3)prior=es_prior.model_prior(len(event_labels))[0]plot_data(data,prior)plt.text(1.5,8.8,'Event 1')plt.text(8.2,4.3,'Event 2')plt.text(15.5,8.8,'Event 3')plt.show()#%% Fitting simulation #2
animate_fit(fit,'fit_noms.gif')#%% Fitting simulation #2 with merge/split
animate_fit(fit_split_merge,'fit_ms.gif')#%% Real fMRI data
sherlock=dd.io.load('sherlock.h5')data=sherlock['BOLD'].mean(2).Thuman_bounds=sherlock['human_bounds']plt.figure(figsize=(10,3))data_z=stats.zscore(data.T,axis=0)plt.imshow(data_z[:20,:100],origin='lower')plt.xlabel('Time')plt.ylabel('Regions')plt.xticks(np.arange(0,100,10))plt.yticks([])plt.show()#%% Fitting real fMRI data
es=EventSegment(60)es.fit(data)no_ms_bounds=np.where(np.diff(np.argmax(es.segments_[0],axis=1)))[0]es_ms=EventSegment(60,split_merge=True)es_ms.fit(data)ms_bounds=np.where(np.diff(np.argmax(es_ms.segments_[0],axis=1)))[0]#%% Plots and stats
print(human_match(no_ms_bounds,human_bounds,data.shape[0]))print(human_match(ms_bounds,human_bounds,data.shape[0]))plt.figure(figsize=(6,3))plt.axis([0,480,0,3])plot_bounds(human_bounds,0)plot_bounds(ms_bounds,1)plot_bounds(no_ms_bounds,2)plt.xlabel('Timepoints')plt.yticks([0.5,1.5,2.5],['Human','Split-Merge HMM','Original HMM'])foriinrange(len(human_bounds)):ifnp.any(np.abs(ms_bounds-human_bounds[i])<=3)and \
notnp.any(np.abs(no_ms_bounds-human_bounds[i])<=3)and \
human_bounds[i]>140:hb=human_bounds[i]plt.gca().add_patch(patches.Rectangle((hb-6,0),12,2,color='k',fill=False))plt.show()
The end of this month will mark the end of my first year as a tenure-track assistant professor. I don’t know if I have much helpful advice to give, since I’m still new enough to the job that it’s hard for me to know what I’ve been doing right or wrong, and I’m very grateful to my collaborators and colleagues in my department for bearing with me as I’ve bumbled my way through my new responsibilities this year. But I do think I can shed some light on what junior faculty life is like, especially for grad students or postdocs who are, like I was, spending a lot of time trying to figure out whether academia is a career path worth attempting. (Though I admire those who were able to easily make up their minds - in grad school I asked a fellow student whether he wanted to pursue a tenure-track job, and he responded with a string of profanity that I will just translate here as “No.”)
I think this video sums up pretty well how this year has gone:
Almost all of the responsibilities in this job are things I love doing - there are just a lot of them, usually way too many to possibly be completed by one person. Being buried by tons of great things is quite a nice place to be, as long as you don’t mind the chaos:
Mentoring trainees
I devote the biggest chunk of my time to working with the trainees in lab, which basically means that I get to brainstorm experiments, debug analyses, and talk about science with super-smart people for most of the day. Recruiting lab members seemed like a huge gamble when I started last year (can I know if I want to work closely with someone for 5+ years after meeting them for one day?), but I’m amazed at how much my mentees have accomplished: two were accepted into top PhD programs, we developed multiple new experimental paradigms from scratch, submitted abstracts, drafted a review article, and set up half a dozen pieces of new equipment.
Teaching
Groaning about (and trying to get out of) teaching is a favorite pastime for research-oriented faculty, but honestly I’ve loved teaching more than I expected. I’ve been able to design two of my own seminars and modify an existing course, so most of the time I get to talk about things that I care about, and I’ve been able to convince students to care about them too! Also, positive teaching evaluation comments are some of the most meaningful and validating bits of praise I’ve ever gotten in my career.
Faculty/trainee recruiting
As a well-known research institution, we get bombarded with applications from prospective PhD students, postdocs, and faculty, and I’ve spent a great deal of time interviewing candidates and attending job talks. Speaking with all these enthusiastic current and future scientists is bittersweet, since more extremely-well-qualified people apply for positions than we could ever accommodate. This is especially true for faculty searches - multiple times this year I’ve been interviewing candidates who are objectively more accomplished researchers than I am, and most didn’t end up with an offer.
Grants
Writing grants was always presented to me as the major downside of a faculty position, and there is certainly a lot of stress involved - suddenly I am responsible for running a small business on which multiple people depend for their salaries, and the process by which grants are evaluated is unpredictable at best. But I’ve found putting together grants to actually be quite useful for thinking more long-term about my research goals, and for providing opportunities to build new collaborations and connect with other faculty members.
Research
I’m still trying to carve out some time each week to do at least a little of my own research, writing some analysis code or testing out ideas that I could pass on to trainees if they seem promising. Looking at senior faculty it seems like this will probably gets squeezed out of my schedule at some point, but right now I still look forward to spending some time with my headphones on fiddling with python code.
Talks and writing
At the end of the day, the primary way I’ll be evaluated is based on how productively I get my lab’s research out into the world in talks and papers. Effective speaking and writing is a hard, time-consuming process, and even as I’ve become much better at it over the years I still don’t know how to do it quickly. It is some consolation to me that even professional authors haven’t found any other way to communicate ideas aside from repeatedly writing the wrong thing and crossing it out, until finding something that works.
Administration and departmental service
Not having a boss in the traditional sense is great in many, many ways, but the downside is that it means that a lot of paperwork tends to flow in my direction. There are also a bunch of advisory and committee jobs in the department that need to get done, but which no one particularly wants to do - luckily my department has been pretty good about insulating junior faculty from these, so I haven’t had much of this dumped on my plate so far.
All airports, he had long ago decided, look very much the same. It doesn’t actually matter where you are, you are in an airport: tiles and walkways and restrooms, gates and newsstands and fluorescent lights. This airport looked like an airport.
-Neil Gaiman, American Gods
Each scene of a movie (or paragraph of a story) generates a pattern of activity in the viewer’s brain, and I showed in my last paper that changes in these activity patterns correspond to new events happening in the story. But it is still mysterious exactly what information the brain is keeping track of in these activity patterns. We know that movie and audiobook versions of the same story generate similar patterns in many brain regions, which means that the information must be pretty abstract. Can we push this even farther? Can we find pattern similarities between different narratives that describe events from the same “template”?
In my new paper we studied a kind of template called an event script, which describes a typical sequence of events that occurs in the world. For example, when you walk into a restaurant you have detailed expectations about what is going to happen next - you are going to be seated at a table, then given menus, then order your food, and then the food will come. Our hypothesis was that some brain regions would track this script information, and should look similar for any story about restaurants regardless of the specific characters and storyline of this particular narrative.
We showed subjects movies and audiobooks of stories taking place in restaurants and stories taking place in airports. Here are examples of two of the restaurant movies (all of the stories are publicly available here):
We then looked for brain regions that seemed to be tracking the restaurant or airport script during all of the stories, and found a whole network of regions:
An especially important region here is the medial prefrontal cortex, which is the part of your brain right behind the middle of your forehead. We found that this region only tracked the script when it made logical sense - if we scrambled the order of the script (e.g. showed people getting food before they ordered) then it no longer bothered to track what was going on.
I also used some of the analysis tools I previously developed for matching up brain data during perception and recall of the same story to find correspondences between different stories with the same script template. For example, I can use brain activity from the superior frontal gyrus to figure out which parts of the “Up in the Air” story and the “How I Met Your Mother” story take place in the same places in the airport. Here are snippets of the stories that show similar patterns of brain activity:
Script event
Up in the Air
How I Met Your Mother
Enter aiport
Ryan looked up from his boarding pass and sighed. There was his new partner Natalie, awkwardly climbing out of a taxi at the curb of the airport.
Barney and Quinn walked into the airport pulling their matching pink tiger-stripe suitcases. Barney leaned over and kissed her on the cheek.
Airport security
Ryan shrugged. “Look at the other lines. I never get behind people traveling with infants - I’ve never seen a stroller collapse in less than twenty minutes. Old people are worse - their bodies are littered with hidden metal and they never seem to appreciate how little time they have left on earth.”
The guard motioned to several others for backup. “Sir, you need to open this box.” “Oh, I can’t do that. Magician’s code. A magician never reveals his tricks. The only person I could possibly reveal the trick to is another magician.”
Boarding gate
He stopped halfway to their gate and pointed at a luggage store. “If you’re going to be flying with me, you need to get a carry-on bag. You know how much time you lose by checking in?”
She tried to interrogate him as they sat in front of the gate, but he refused to spill the beans. “I told you, magician’s code.”
On plane
“I like my own stuff. Don’t you like feeling connected to home?” Ryan laughed. “This is where I live. All the things you probably hate about traveling - the recycled air, the artificial lighting - are warm reminders that I am home.”
In its center was a diamond ring, which Barney plucked from the flower and held out to Quinn. “Quinn, will you marry me?”
I’m currently analyzing some additional data from these subjects, collected while they tried to retell all 16 stories from memory. Our hypothesis is that these script templates should also be useful when trying to remember events, since they give us clues about what kinds of events to search for in our memories. I’m also fascinated by how these scripts get learned, and am hoping to study this learning process both in adults (who are learning a new scripts in the lab) and in children (who are learning real scripts over the course of years).
Much of the conversation about research methods in science has focused on the “replication crisis” - the fact that many classic studies (especially in psychology) are often not showing the same results when performed carefully by independent research groups. Although there are some debates about exactly how bad the problem is, a consensus is emerging about how to improve the ways we conduct experiments and analyses: pre-registering study hypotheses before seeing the data, using larger sample sizes, being more willing to publish (informative) null results, and maybe being more conservative about what evidence counts as “proof.”
But there is actually an even simpler problem we haven’t fully tackled, which is not “replicability” (being able to get the same result in new data from a new experiment) but “reproducibility” - the ability to demonstrate how we got the result from the original data in the first place. Being able trace and record the exact path from data to results is important for documenting precisely how the analysis works, and allows other researchers to examine the details for themselves if they are skeptical. It also makes it much easier for future work (either by the same authors or others) to keep analyses comparable across different experiments.
Describing how data was analyzed is of course supposed to be one of the main points of a published paper, but in practice it is almost impossible to recreate the exact processing pipeline of a study just from reading the paper. Here are some real examples that I have experienced firsthand in my research:
Trying to replicate a results from papers that used a randomization procedure called phase scrambling, I realized that there are actually at least two ways of doing this scrambling and papers usually don’t specify which one they use
Confusion over exactly what probability measure was calculated in a published study set off a minor panic when the study authors started to think their code was wrong, before realizing that their analysis was actually working as intended
Putting the same brain data into different versions of AFNI (a neuroimaging software package) can produce different statistical maps, due to a change in the way the False Discovery Rate is calculated
A collaborator was failing to reproduce one of my results even with my code - turned out that the code worked in MATLAB versions 2015b and 2017b but not 2017a (for reasons that are still unclear)
These issues show that reproducible research actually requires three pieces:
Publicly available data
Open-source code
A well-defined computing environment
The first two things we know basically how to do, at least in theory - data can be uploaded to a number of services that are typically free to researchers (and standards are starting to emerge for complex data formats like neuroimaging data), and code can be shared (and version-controlled) through platforms like GitHub. But the last piece has been mostly overlooked - how can we take a “snapshot” of all the behind-the-scene infrastructure, like the programming language version and all the libraries the code depends on? This is honestly often the biggest barrier to reproducing results - downloading data and code is easy, but actually getting the code to run (and run exactly as it did for the original analysis) can be a descent into madness, especially on a highly-configurable linux machine.
For my recent preprint, I tried out a possible solution to this problem: an online service called CodeOcean. This platform allow you to create an isolated “capsule” that contains your data, your code, and a description of the programming environment (set up with a simple GUI). You can then execute your code (on their servers), creating a verified set of results - the whole thing is then labeled with a DOI, and is publicly viewable with just a browser. Interestingly the public capsule is still live, meaning that anyone can edit the code and click Run to see how the results change (any changes they make affect only their own view of the capsule). Note that I wouldn’t recommend blindly clicking Run on my capsule since the analysis takes multiple hours, but if you’re interested in messing with it you can edit the run.sh file to only conduct a manageable subset of the analyses (e.g. only on a single region of interest). CodeOcean is still under development, and there are a number of features I haven’t tried yet (including the ability to run live Jupyter Notebooks, and a way to create a simple GUI for exposing parameters in your code).
For now this is set up as a post-publication (or post-preprint) service and isn’t intended for actually working on the analyses (the computing power you have access to is limited and has a quota), but as cloud computing continues to become more convenient and affordable I could eventually see entire scientific workflows moving online.
[I wrote these posts during the Society for Neuroscience 2017 meeting, as one of the Official Annual Meeting Bloggers. These blog posts originally appeared on SfN’s Neuronline platform.]
SuperEEG: ECoG data breaks free from electrodes
The “gold standard” for measuring neural activity in human brains is ECoG (electrocorticography), using electrodes implanted directly onto the surface of the brain. Unlike methods that measure blood oxygenation (which have poor temporal resolution) or that measure signals on the scalp (which have poor spatial resolution), ECoG data has both high spatial and temporal precision. Most of the ECoG data that has been collected comes from patients who are being treated for epileptic seizures and have had electrodes implanted in order to determine where the seizures are starting.
The big problem with ECoG data, however, is that each patient typically only has about 150 implanted electrodes, meaning that we can only measure brain activity in 150 spots (compared to about 100,000 spots for functional MRI). It would seem like there is no way around this - if you don’t measure activity from some part of the brain, then you can’t know anything about what is happening there, right?
Actually, you can, or at least you can guess! Lucy Owen, Andrew Heusser, and Jeremy Manning have developed a new analysis tool called SuperEEG, based on the idea that measuring from one region of the brain can actually tell you a lot about another unmeasured region, if the two regions are highly correlated (or anti-correlated). By using many ECoG subjects to learn the correlation structure of the brain, we can extrapolate from measurements in a small set of electrodes to estimate neural activity across the whole brain.
This breaks ECoG data free from little islands of electrodes and allows us to carry out analyses across the brain. Not all brain regions can be well-estimated using this method (due to the typical placement locations of the electrodes and the correlation structure of brain activity), but it works surprisingly well for most of the cortex:
This could also help with the original medical purpose of implanting these electrodes, by allowing doctors to track seizure activity in 3D as it spreads through the brain. It could even be used to help surgeons choose the locations where electrodes should be placed in new patients, to make sure that seizures can be tracked as broadly and accurately as possible.
Hippocampal subregions growing old together
To understand and remember our experiences, we need to think both big and small. We need to keep track of our spatial location at broad levels (“what town am I in?”) all the way down to precise levels (“what part of the room am I in?”). We need to keep track of time on scales from years to fractions of a second. We need to access our memories at both a coarse grain (“what do I usually bring to the beach?”) and a fine grain (“remember that time I forgot the sunscreen?”).
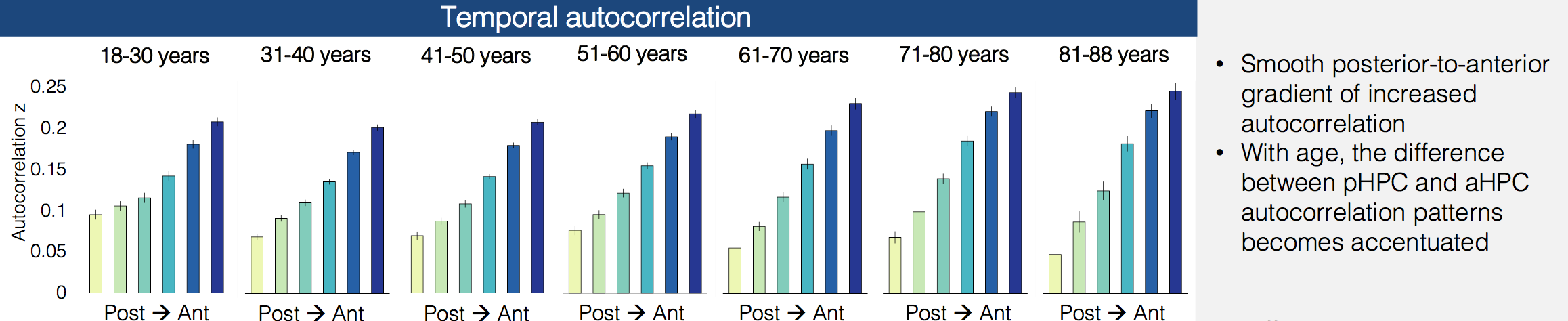
Data from both rodents and humans has suggested that different parts of the hippocampus keep track of different levels of granularity, with posterior hippocampus focusing on the fine details and anterior hippocampus seeing the bigger picture. Iva Brunec and her co-authors recently posted a preprint showing that temporal and spatial correlations change along the long axis of the hippocampus - in anterior hippocampus all the voxels are similar to each other and change slowly over time, while in posterior hippocampus the voxels are more distinct from each other and change more quickly over time.
In their latest work, they look at how these functional properties of the hippocampus change over the course of our lives. Surprisingly, this anterior-posterior distinction actually increases with age, becoming the most dramatic in the oldest subjects in their sample.
The interaction between the two halves of the hippocampus also changes - while in young adults activity timecourses in the posterior and anterior hippocampus are uncorrelated, they start to become anti-correlated in older adults, perhaps suggesting that the complementary relationship between the two regions has started to break down. Also, their functional connectivity with the rest of the brain shifts over time, with posterior hippocampus decoupling from posterior medial regions and anterior hippocampus increasing its coupling to medial prefrontal regions.
These results raise a number of intriguing questions about the cause of these shifts, and their impacts on cognition and memory throughout the lifespan. Is this shift toward greater coupling with regions that represent coarse-grained schematic information compensating for degeneration in regions that represent details? What is the “best” balance between coarse- and fine-timescale information for processing complex stimuli like movies and narratives, and at what age is it achieved? How do these regions mature before age 18, and how do their developmental trajectories vary across people? By following the analysis approach of Iva and her colleagues on new datasets, we should hopefully be able to answer many of these questions in future studies.
The Science of Scientific Bias
This year’s David Kopf lecture on Neuroethics was given by Dr. Jo Handelsman, entitled “The Fallacy of Fairness: Diversity in Academic Science”. Dr. Handelsman is a microbiologist who recently spent three years as the Associate Director for Science at the White House Office of Science and Technology Policy, and has also led some of the most well-known studies of gender bias in science.
She began her talk by pointing out that increasing diversity in science is not only a moral obligation, but also has major potential benefits for scientific discovery. Diverse groups have been shown to produce more effective, innovative, and well-reasoned solutions to complex problems. I think this is especially true in psychology - if we are trying to create theories of how all humans think and act, we shouldn’t be building teams composed of a thin slice of humanity.
Almost all scientists agree in principle that we should not be discriminating based on race or gender. However, the process of recruiting, mentoring, hiring, and promotion relies heavily on “gut feelings” and subtle social cues, which are highly susceptible to implicit bias. Dr. Handelsman covered a wide array of studies over the past several decades, ranging from observational analyses to randomized controlled trials of scientists making hiring decisions. I’ll just mention two of the studies she described which I found the most interesting:
How it is possible that people can be making biased decisions, but still think they were objective when they reflect on those decisions? A fascinating study by Uhlmann & Cohen showed that subjects rationalized biased hiring decisions after the fact by redefining their evaluation criteria. For example, when choosing whether to hire a male candidate or a female candidate, who both had (randomized) positive and negative aspects to their resumes, the subjects would decide that the positive aspects of the male candidate were the most important for the job and that he therefore deserved the position. This is interestingly similar to the way that p-hacking distorts scientific results, and the solution to the problem may be the same. Just as pre-registration forces scientists to define their analyses ahead of time, Uhlmann & Cohen showed that forcing subjects to commit to their importance criteria before seeing the applications eliminated the hiring bias.
Even relatively simple training exercises can be effective in making people more aware of implicit bias. Dr. Handelsman and her colleagues created a set of short videos called VIDS (Video Interventions for Diversity in STEM), consisting of narrative films illustrating issues that have been studied in the implicit bias literature, along with expert videos describing the findings of these studies. They then ran multiple experiments showing that these videos were effective at educating viewers, and made them more likely to notice biased behavior. I plan on making these videos required viewing in my lab, and would encourage everyone working in STEM to watch them as well (the narrative videos are only 30 minutes total).
Drawing out visual memories
If you close your eyes and try to remember something you saw earlier today, what exactly do you see? Can you visualize the right things in the right places? Are there certain key objects that stand out the most? Are you misremembering things that weren’t really there?
Visual memory for natural images has typically been studied with recognition experiments, in which subjects have to recognize whether an image is one they have seen before or not. But recognition is quite different from freely recalling a memory (without being shown it again), and can involve different neural mechanisms. How can we study visual recall, testing whether the mental images people are recalling are correct?
One way option is to have subjects give verbal descriptions of what they remember, but this might not capture all the details of their mental representation, such as the precise relationships between the objects or whether their imagined viewpoint of the scene is correct. Instead, NIMH researchers Elizabeth Hall, Wilma Bainbridge, and Chris Baker had subjects draw photographs from memory, and then analyzed the contents of those drawings.
This is a creative but challenging approach, since it requires quantitatively characterizing how well the drawings (all 1,728!) match the original photographs. They crowdsource this task using Amazon Mechanical Turk, getting high-quality ratings that include: how well can the original photograph be identified based on the drawing, what objects were correctly drawn, what objects were falsely remembered as being in the image, and how close the objects were to their correct locations. There are also “control” drawings made by subjects with full information (that get to look at the image while they draw) or minimal information (just a category label) that were rated for comparison.
The punchline is that subjects can remember many of the images, and produce surprisingly detailed drawings that are quite similar to those drawn by the control group that could look at the pictures. They reproduce the majority of the objects, place them in roughly the correct locations, and draw very few incorrect objects, making it very easy to match the drawings with the original photographs. The only systematic distortion is that the drawings depicted the scenes as being slightly farther away than they actually were, which nicely replicates previous results on boundary extension.
This is a neat task that subjects are remarkably good at (which is not always the case in memory experiments!), and could be a great tool for investigating the neural mechanisms of naturalistic perception and memory. Another intriguing SfN presentation showed that is possible to have subjects draw while in an fMRI scanner, allowing this paradigm to be used in neuroimaging experiments. I wonder if this approach could also be extended into drawing comic strips of remembered events that unfold over time, or to illustrate mental images based on stories told through audio or text.

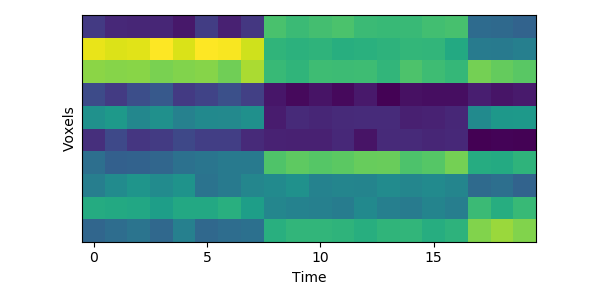
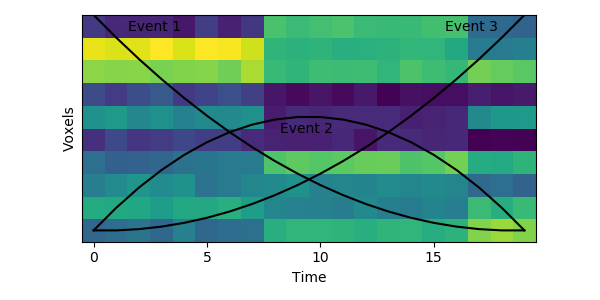
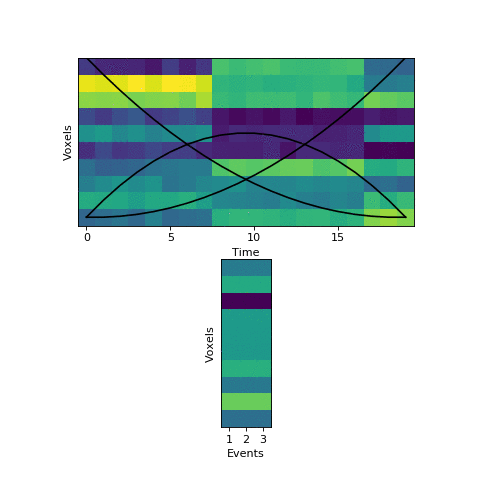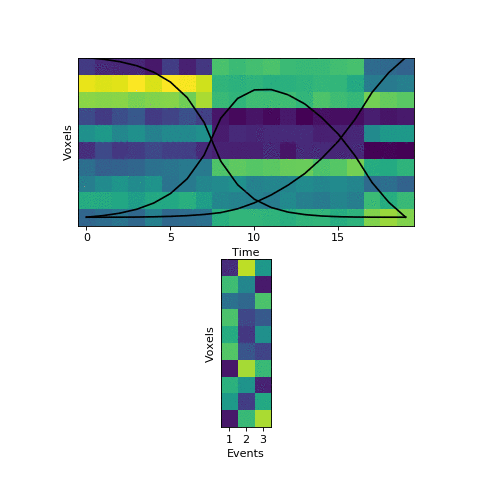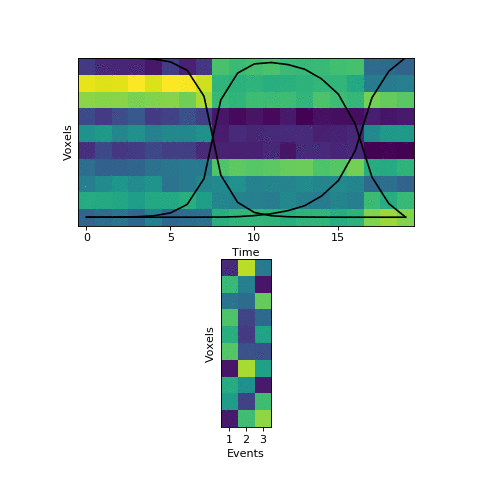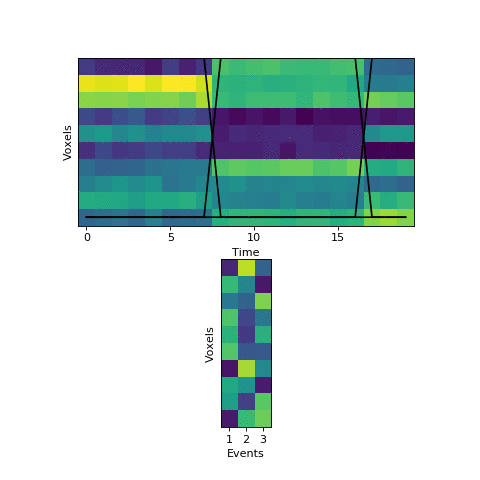
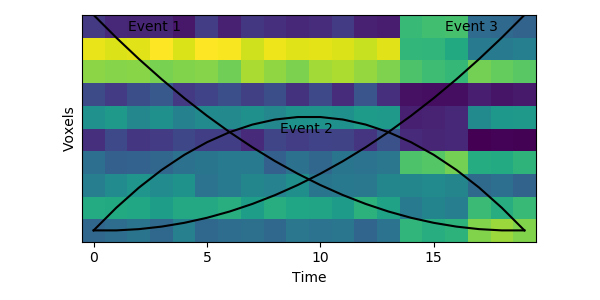
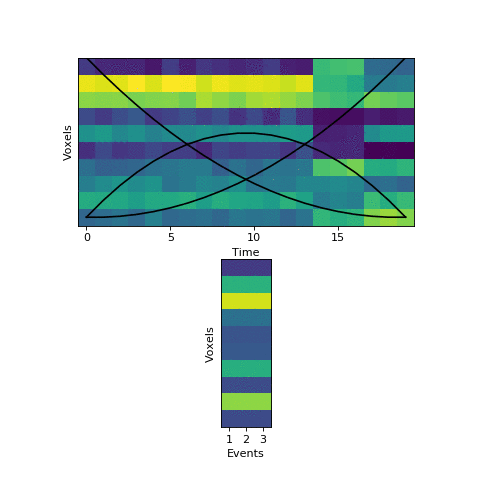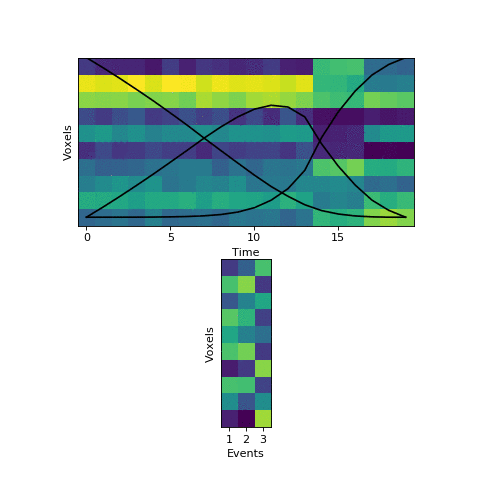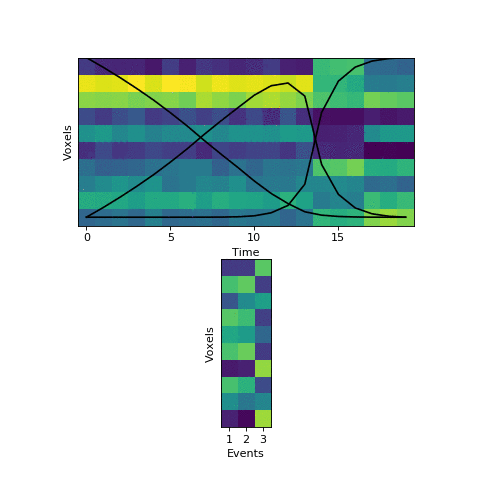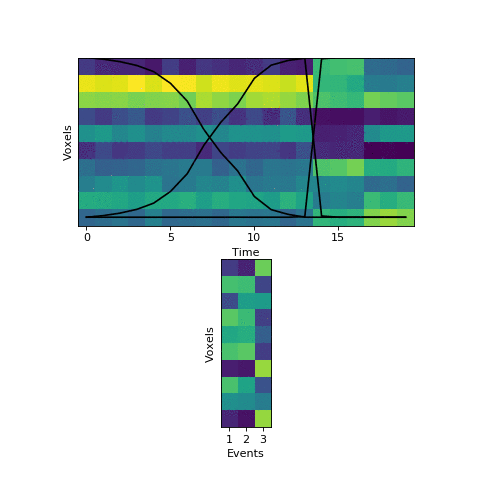
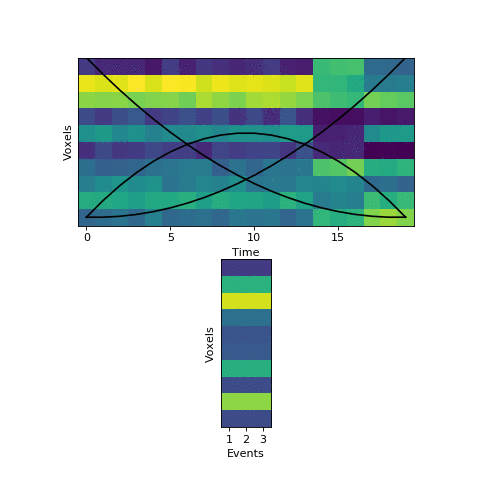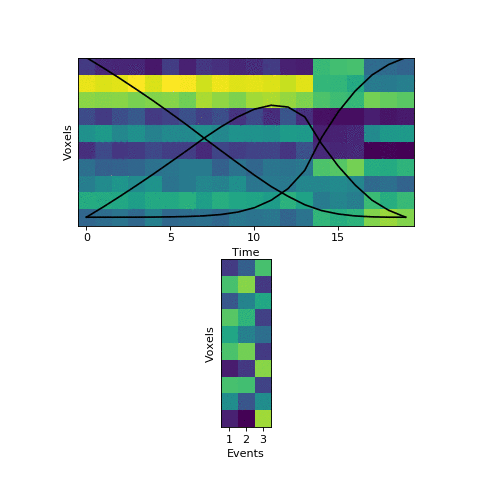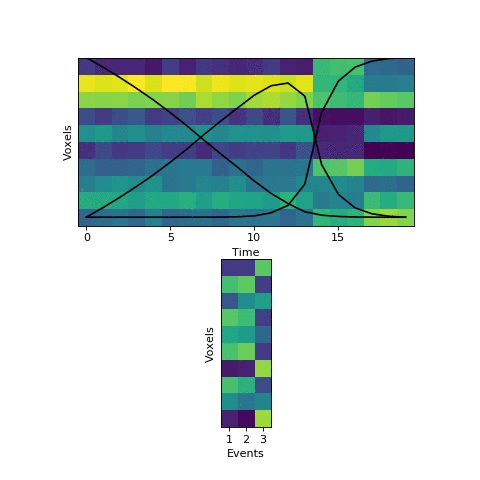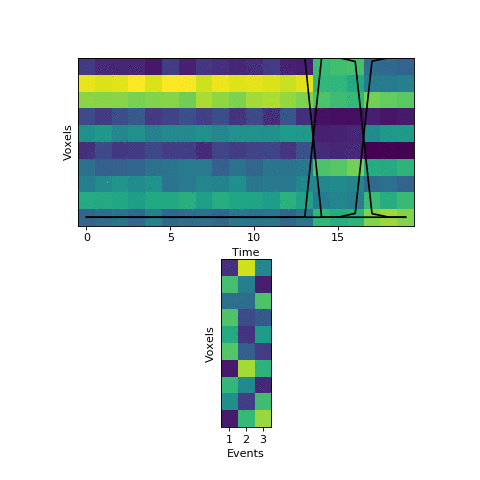
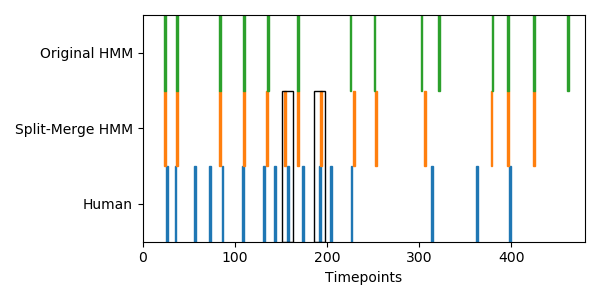

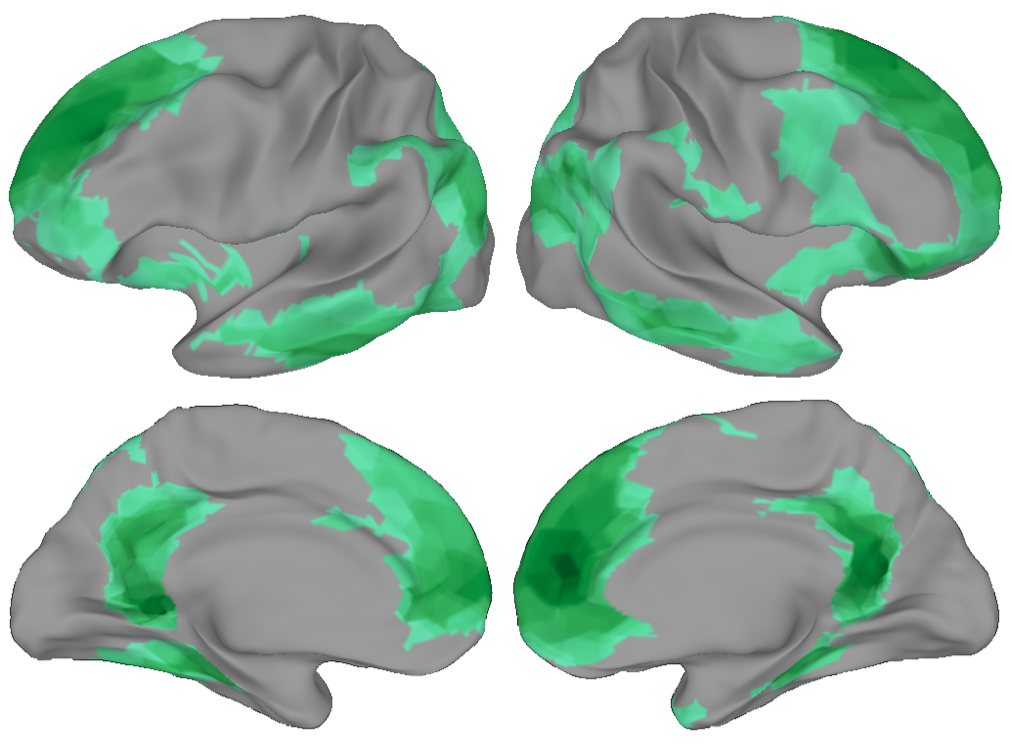
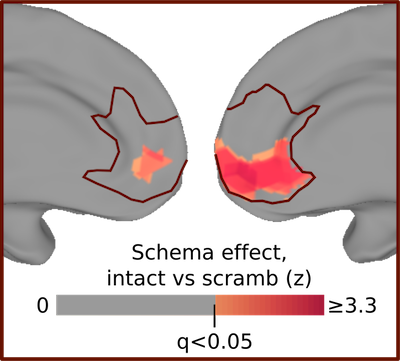
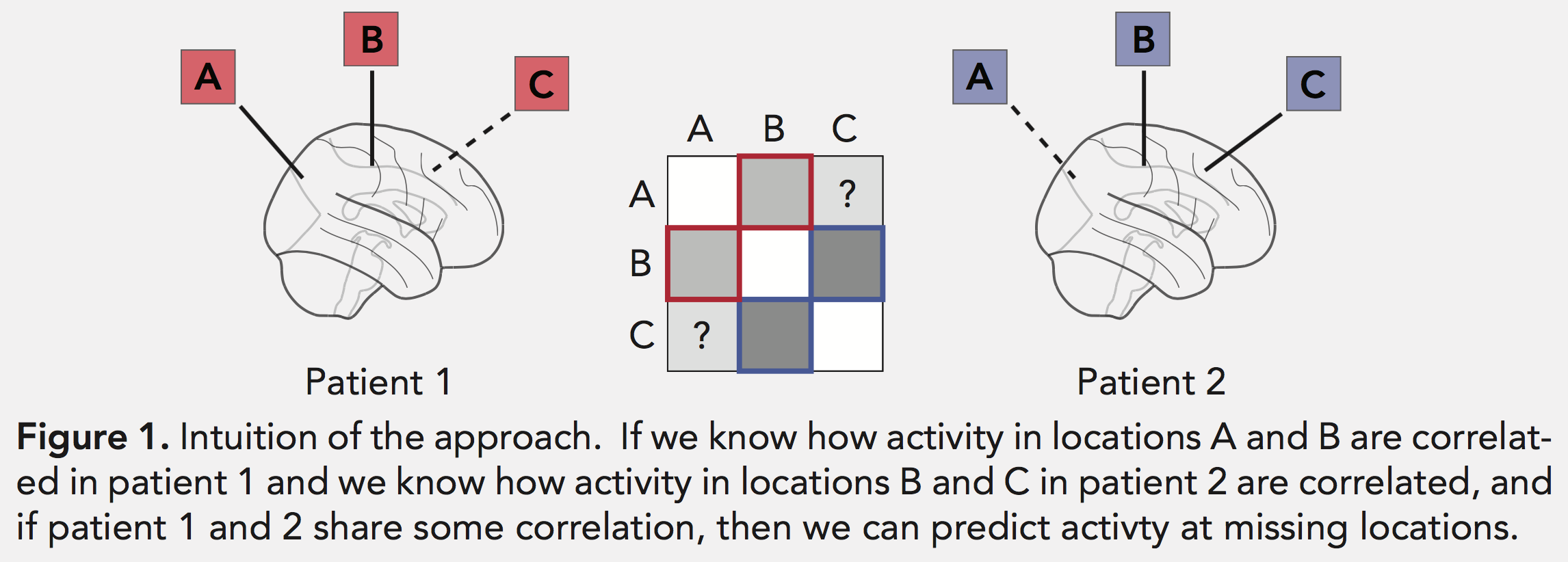 Figure from
Figure from 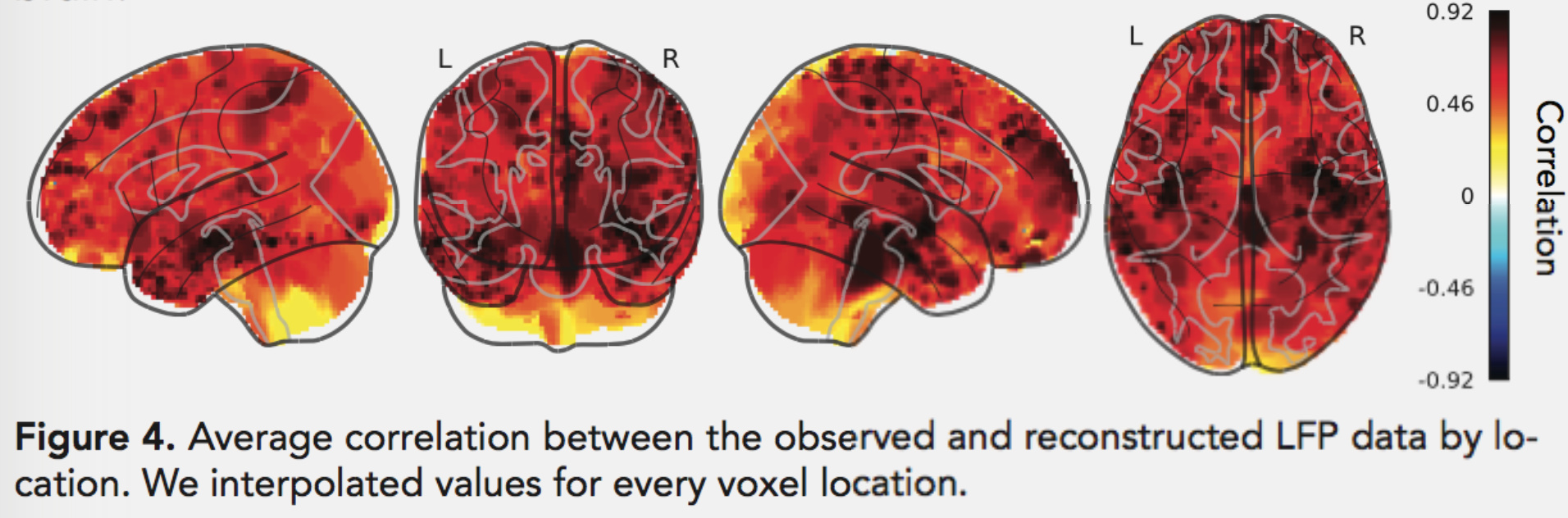
 The interaction between the two halves of the hippocampus also changes - while in young adults activity timecourses in the posterior and anterior hippocampus are uncorrelated, they start to become anti-correlated in older adults, perhaps suggesting that the complementary relationship between the two regions has started to break down. Also, their functional connectivity with the rest of the brain shifts over time, with posterior hippocampus decoupling from posterior medial regions and anterior hippocampus increasing its coupling to medial prefrontal regions.
The interaction between the two halves of the hippocampus also changes - while in young adults activity timecourses in the posterior and anterior hippocampus are uncorrelated, they start to become anti-correlated in older adults, perhaps suggesting that the complementary relationship between the two regions has started to break down. Also, their functional connectivity with the rest of the brain shifts over time, with posterior hippocampus decoupling from posterior medial regions and anterior hippocampus increasing its coupling to medial prefrontal regions. These results raise a number of intriguing questions about the cause of these shifts, and their impacts on cognition and memory throughout the lifespan. Is this shift toward greater coupling with regions that represent coarse-grained schematic information compensating for degeneration in regions that represent details? What is the “best” balance between coarse- and fine-timescale information for processing complex stimuli like movies and narratives, and at what age is it achieved? How do these regions mature before age 18, and how do their developmental trajectories vary across people? By following the analysis approach of Iva and her colleagues on new datasets, we should hopefully be able to answer many of these questions in future studies.
These results raise a number of intriguing questions about the cause of these shifts, and their impacts on cognition and memory throughout the lifespan. Is this shift toward greater coupling with regions that represent coarse-grained schematic information compensating for degeneration in regions that represent details? What is the “best” balance between coarse- and fine-timescale information for processing complex stimuli like movies and narratives, and at what age is it achieved? How do these regions mature before age 18, and how do their developmental trajectories vary across people? By following the analysis approach of Iva and her colleagues on new datasets, we should hopefully be able to answer many of these questions in future studies.

