
How deep is the brain?
08 Jul 2016Recent AI advances in speech recognition, game-playing, image understanding, and language translation have all been based on a simple concept: multiply some numbers together, set some of them to zero, and then repeat. Since “multiplying and zeroing” doesn’t inspire investors to start throwing money at you, these models are instead presented under the much loftier banner of “deep neural networks.” Ever since the first versions of these networks were invented by Frank Rosenblatt in 1957, there has been controversy over how “neural” these models are. The New York Times proclaimed these first programs (which could accomplish tasks as astounding as distinguishing shapes on the left side versus shapes on the right side of a paper) to be “the first device to think as the human brain.”

Deep neural networks remained mostly a fringe idea for decades, since they typically didn’t perform very well, due (in retrospect) to the limited computational power and small dataset sizes of the era. But over the past decade these networks have begun to rival human capabilities on highly complicated tasks, making it more plausible that they could really be emulating human brains. We’ve also started to get much better data about how the brain itself operates, so we can start to make some comparisons.
At least for visual images, a consensus started to emerge about what these deep neural networks were actually doing, and how it matched up to the brain. These networks operate as a series of “multiply and zero” filters, which build up more and more complicated descriptions of the image. The first filter looks for lines, the second filter combines the lines into corners and curves, the third filter combines the corners into shapes, etc. If we look in the visual system of the brain, we find a similar layered structure, with the early layers of the brain doing something like the early filters of the neural networks, and later layers of the brain looking like the later filters of the neural networks.
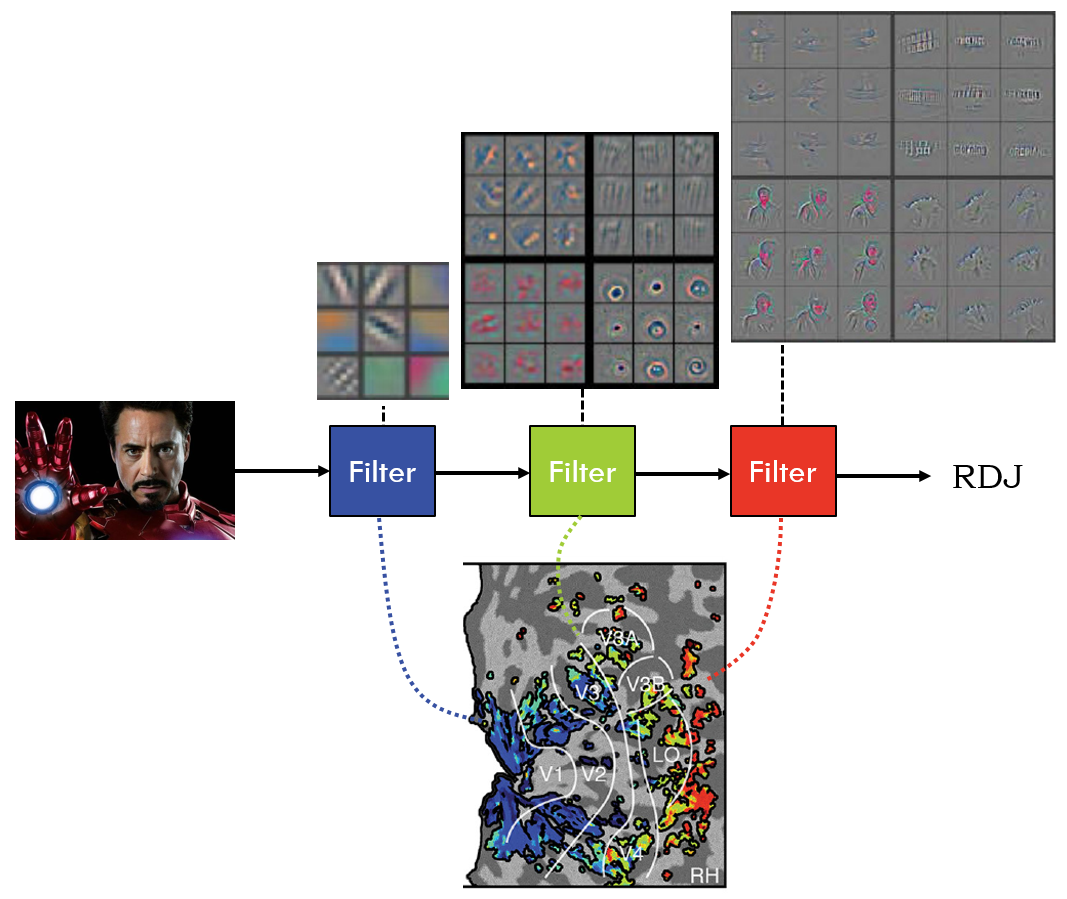 Zeiler & Fergus 2014, Güçlü & van Gerven 2015
Zeiler & Fergus 2014, Güçlü & van Gerven 2015
It seemed like things were mostly making sense, until two recent developments:
- The best-performing networks started requiring a lot of filters. For example, one of the current state-of-the-art networks uses 1,001 layers. Although we don’t know exactly how many layers the brain’s visual system has, it is almost certainly less than 100.
- These networks actually don’t get that much worse if you randomly remove layers from the middle of the chain. This makes very little sense if you think that each filter is combining shapes from the previous filter - it’s like saying that you can skip one step of a recipe and things will still work out fine.
Should we just throw up our hands and say that these networks just have way more layers than the brain (they’re “deeper”) and we can’t understand how they work? Liao and Poggio have a recent preprint that proposes a possible solution to both of these issues: maybe the later layers are all doing the same operation over and over, so that the filter chain looks like this:

Why would you want to repeat the same operation many times? Often it is a lot easier to figure out how to make a small step toward your goal and then repeat, instead of going directly to the goal. For example, imagine you want to set a microwave for twelve minutes, but all the buttons are unlabeled and in random positions. Typing 1-2-0-0-GO is going to take a lot of trial and error, and if you mess up in the middle you have to start from scratch. But if you’re able to find the “add 30 seconds” button, you can just hit it 24 times and you’ll be set. This also shows why skipping a step isn’t a big deal - if you hit the button 23 times instead, it shouldn’t cause major issues.
But if the last layers are just the same filter over and over, we can actually just replace them with a single filter in a loop, that takes its output and feeds it back into its input. This will act like a deep network, except that the extra layers are occurring in time:

So Liao and Poggio’s hypothesis is that very deep neural networks are like a brain that is moderately deep in both space and time. The true depth of the brain is hidden, since even though it doesn’t have a huge number of regions it gets to run these regions in loops over time. Their paper has some experiments to show that this is plausible, but it will take some careful comparisons with neuroscience data to say if they are correct.
Of course, it seems inevitable that at some point in the near future we will in fact start building neural networks that are “deeper” than the brain, in one way or another. Even if we don’t discover new models that can learn better than a brain can, computers have lots of unfair advantages - they’re not limited to a 1500 cm3 skull, they have direct access to the internet, they can instantly teach each other things they’ve learned, and they never get bored. Once we have a neural network that is similar in complexity to the human brain but can run on computer hardware, its capabilities might be advanced enough to design an even more intelligent machine on its own, and so on: maybe the “first ultraintelligent machine is the last invention that man need ever make.” (Vernor Vinge)
Comments? Complaints? Contact me @ChrisBaldassano