
Connecting past and present in visual perception
25 Oct 2016There are two kinds of people in the world—those who divide everything in the world into two kinds of things and those who don’t.
Kenneth Boulding
Scientists love dividing the world into categories. Whenever we are trying to study more than 1 or 2 things at a time, our first instinct is to sort them into boxes based on their similarities, whether we’re looking at animals, rocks, stars, or diseases.
There have been many proposals on how to divide up the human visual system: regions processing coarse vs. fine structure, or small objects vs. big objects, or central vs. peripheral information. In my new paper, Two distinct scene processing networks connecting vision and memory, I argue that regions activated by photographic images can be split into two different networks.
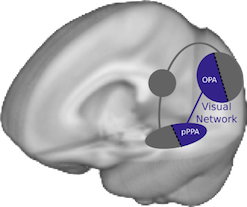

The first group of scene-processing regions (near the back of the brain) care only about the image that is currently coming in through your eyes. They are looking for visual features like walls, landmarks, and architecture that will help you determine the structure of the environment around you. But they don’t try to keep track of this information over time - as soon as you move your eyes, they forget all about the last view of the world.
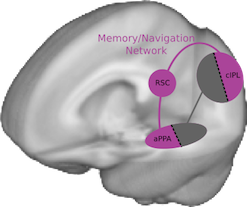

The second group (a bit farther forward) uses the information from the first group to build up a stable model of the world and your place in it. They care less about exactly where your eyes are pointed and more about where you are in the world, creating a 3D model of the room or landscape around you and placing you on a map of what other places are nearby. These regions are strongly linked to your long-term memory system, and show the highest activity in familiar environments.
I am very interested in this second group of regions that integrate information over time - what exactly are they keeping track of, and how do they get information in and out of long-term memory? I have a new manuscript with my collaborators at Princeton (currently working its way through the publication gaunlet) showing that these regions build abstract representations of events in movies and audio narration, and am running a new experiment looking at how event templates we learn over our lifetimes are used to help build these event representations.
Comments? Complaints? Contact me @ChrisBaldassano