02 Aug 2017
Our brains receive a constant stream of information about the world through our senses. Often sci-fi depictions of mind-reading or memory implants depict our experiences and memories as being like a continuous, unbroken filmstrip.
 From The Final Cut, 2004
From The Final Cut, 2004
But if I ask you to describe what has happened to you today, you will usually think in terms of events - snippets of experience that make sense as a single unit. Maybe you ate breakfast, and then brushed your teeth, and then got a phone call. You divide your life into these separate pieces, like how separate memory orbs get created in the movie Inside Out.
 From Inside Out, 2015
From Inside Out, 2015
This grouping into events is an example of chunking, a common concept in cognitive psychology. It is much easier to put together parts into wholes and then think about only the wholes (like objects or events), rather than trying to keep track of all the parts separately. The idea that people automatically perform this kind of event chunking has been relatively well studied, but there are lots of things we don’t understand about how this happens in the brain. Do we directly create event-level chunks (spanning multiple minutes) or do we build up longer and longer chunks in different brain regions? Does this chunking happen within our perceptual systems, or are events constructed afterwards by some separate process? Are the chunks created during perception the same chunks that get stored into long-term memory?
I have a new paper out today that takes a first stab at these questions, thanks to the help of an all-star team of collaborators: Janice Chen, Asieh Zadbood (who also has a very cool and related preprint), Jonathan Pillow, Uri Hasson, and Ken Norman.
The basic idea is simple: if a brain region represents event chunks, then its activity should go through periods of stability (within events) punctuated by sudden shifts (at boundaries between events). I developed an analysis tool that is able to find this kind of structure in fMRI data, determining how many of these shifts happen and when then happen.
The first main result is that we see event chunking in lots of brain regions, and the length of the events seems to build up from short events (seconds or less) in early sensory regions to long events (minutes) in higher-level regions. This suggests that events are an instrinsic part of how we experience the world, and that events are constructed through multiple stages of a hierarchy.
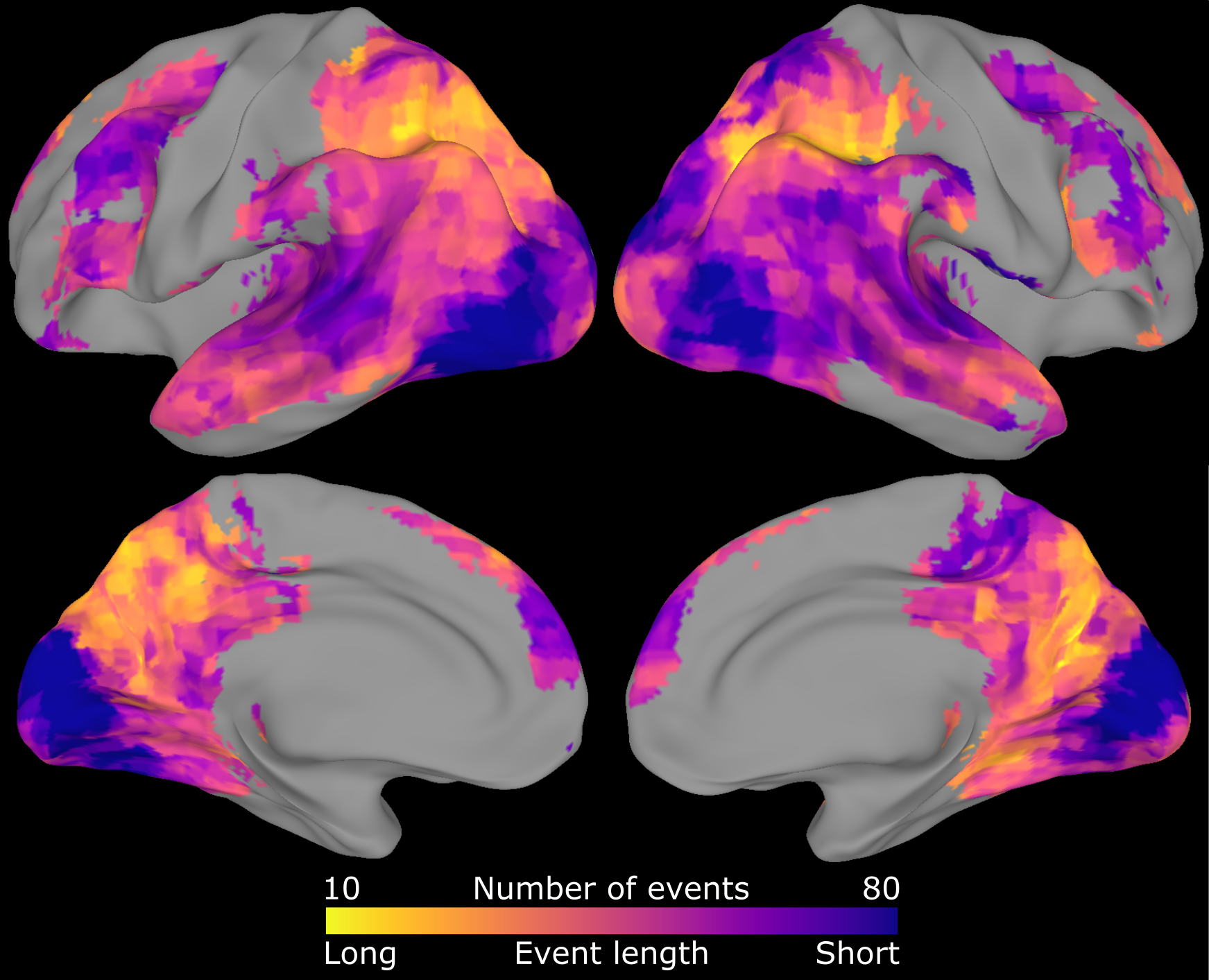
The second main result is that right at the end of these high-level events, we see lots of activity in brain regions the store long-term memories, like the hippocampus. Based on some additional analyses, we argue that these activity spikes are related to storing these chunks so that we can remember them later. If this is true, then our memory system is less like a DVR that constantly records our life, and more like a library of individually-wrapped events.
There are many (many) other analyses in the paper, which explains why it took us about two years to put together in its entirety. One fun result at the end of the paper is that people who already know a story actually start their events a little earlier than people hearing a story for the first time. This means that if I read you a story in the scanner, I can actually make a guess about whether or not you’ve heard this story before by looking at your brain activity. This guessing will not be very accurate for an individual person, so I’m not ready to go into business with No Lie MRI just yet, but maybe in the near future we could have a scientific way to detect Netflix cheaters.
Comments? Complaints? Contact me
@ChrisBaldassano
05 Jun 2017
For most of human history, parents had a pretty good idea of the kind of world they were preparing their children for. Children would be trained to take over their parents’ business, or apprentice in a local trade, or aim for a high-status marriage. Even once children began to have more choice in their futures, it was easy to predict what kind of skills they would need to succeed: reading and handwriting, arithmetic, basic knowledge of science and history.
As technological progress has accelerated, this predictability is starting to break down. Companies like internet search engines didn’t even exist when most of Google’s 70,000 employees were born, and there is no way their parents could have guessed the kind of work they would eventually be doing. Some of the best-known musicians in the world construct songs using software, and don’t play any of the instruments that would have been offered to them in elementary school.
Given this uncertainty, what kinds of skills and interests should I encourage for my own children? Praticing handwriting, as I spent hours doing in school, would almost certainly be a waste. Same goes for mental math beyond small numbers or estimation, now that everyone carries a caculator. Given how computers are slowly seeping into every object in our house, programming seems like a safe answer, until you hear that researchers are currently building systems that can design themselves based on training examples.
Maybe in a couple decades, being creative and artistic will be more important than having STEM skills. Artificial intelligence is still pretty laughably bad at writing stories, and AI-based art tools still require a human at the helm. Even if that changes by the time my kids are starting their careers, there could still be a market for “artisan,” human-made art. Having good emotional intelligence also seems like it will always be helpful, in any world where we have to live with others and with ourselves.
As confusing as this is for me, it will be immensely harder for my children to be parents. I think of this current generation of toddlers as the last human generation - not because humanity is likely to wipe itself out within the next 20 years (though things are looking increasingly worrying on that front), but because I expect that by then humans and technology will start to become inseparable. Even now, being separated from our cell phones feels disconcerting - we have offloaded so much of our thinking, memory, and conversations to our devices that we feel smaller without them. By the time my grandchildren are teenagers, I expect that being denied access to technology will be absolutely crippling, to the point that they no longer have a coherent identity as a human alone.
When a software update could potentially make any skill obsolete, what skills should we cultivate?
Comments? Complaints? Contact me
@ChrisBaldassano
25 Oct 2016
There are two kinds of people in the world—those who divide everything in the world into two kinds of things and those who don’t.
Kenneth Boulding
Scientists love dividing the world into categories. Whenever we are trying to study more than 1 or 2 things at a time, our first instinct is to sort them into boxes based on their similarities, whether we’re looking at animals, rocks, stars, or diseases.
There have been many proposals on how to divide up the human visual system: regions processing coarse vs. fine structure, or small objects vs. big objects, or central vs. peripheral information. In my new paper, Two distinct scene processing networks connecting vision and memory, I argue that regions activated by photographic images can be split into two different networks.
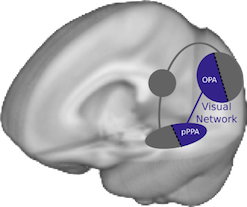

The first group of scene-processing regions (near the back of the brain) care only about the image that is currently coming in through your eyes. They are looking for visual features like walls, landmarks, and architecture that will help you determine the structure of the environment around you. But they don’t try to keep track of this information over time - as soon as you move your eyes, they forget all about the last view of the world.
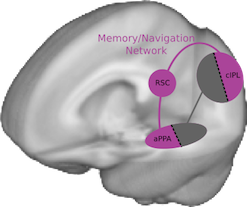

The second group (a bit farther forward) uses the information from the first group to build up a stable model of the world and your place in it. They care less about exactly where your eyes are pointed and more about where you are in the world, creating a 3D model of the room or landscape around you and placing you on a map of what other places are nearby. These regions are strongly linked to your long-term memory system, and show the highest activity in familiar environments.
I am very interested in this second group of regions that integrate information over time - what exactly are they keeping track of, and how do they get information in and out of long-term memory? I have a new manuscript with my collaborators at Princeton (currently working its way through the publication gaunlet) showing that these regions build abstract representations of events in movies and audio narration, and am running a new experiment looking at how event templates we learn over our lifetimes are used to help build these event representations.
Comments? Complaints? Contact me
@ChrisBaldassano
08 Jul 2016
Recent AI advances in speech recognition, game-playing, image understanding, and language translation have all been based on a simple concept: multiply some numbers together, set some of them to zero, and then repeat. Since “multiplying and zeroing” doesn’t inspire investors to start throwing money at you, these models are instead presented under the much loftier banner of “deep neural networks.” Ever since the first versions of these networks were invented by Frank Rosenblatt in 1957, there has been controversy over how “neural” these models are. The New York Times proclaimed these first programs (which could accomplish tasks as astounding as distinguishing shapes on the left side versus shapes on the right side of a paper) to be “the first device to think as the human brain.”

Deep neural networks remained mostly a fringe idea for decades, since they typically didn’t perform very well, due (in retrospect) to the limited computational power and small dataset sizes of the era. But over the past decade these networks have begun to rival human capabilities on highly complicated tasks, making it more plausible that they could really be emulating human brains. We’ve also started to get much better data about how the brain itself operates, so we can start to make some comparisons.
At least for visual images, a consensus started to emerge about what these deep neural networks were actually doing, and how it matched up to the brain. These networks operate as a series of “multiply and zero” filters, which build up more and more complicated descriptions of the image. The first filter looks for lines, the second filter combines the lines into corners and curves, the third filter combines the corners into shapes, etc. If we look in the visual system of the brain, we find a similar layered structure, with the early layers of the brain doing something like the early filters of the neural networks, and later layers of the brain looking like the later filters of the neural networks.
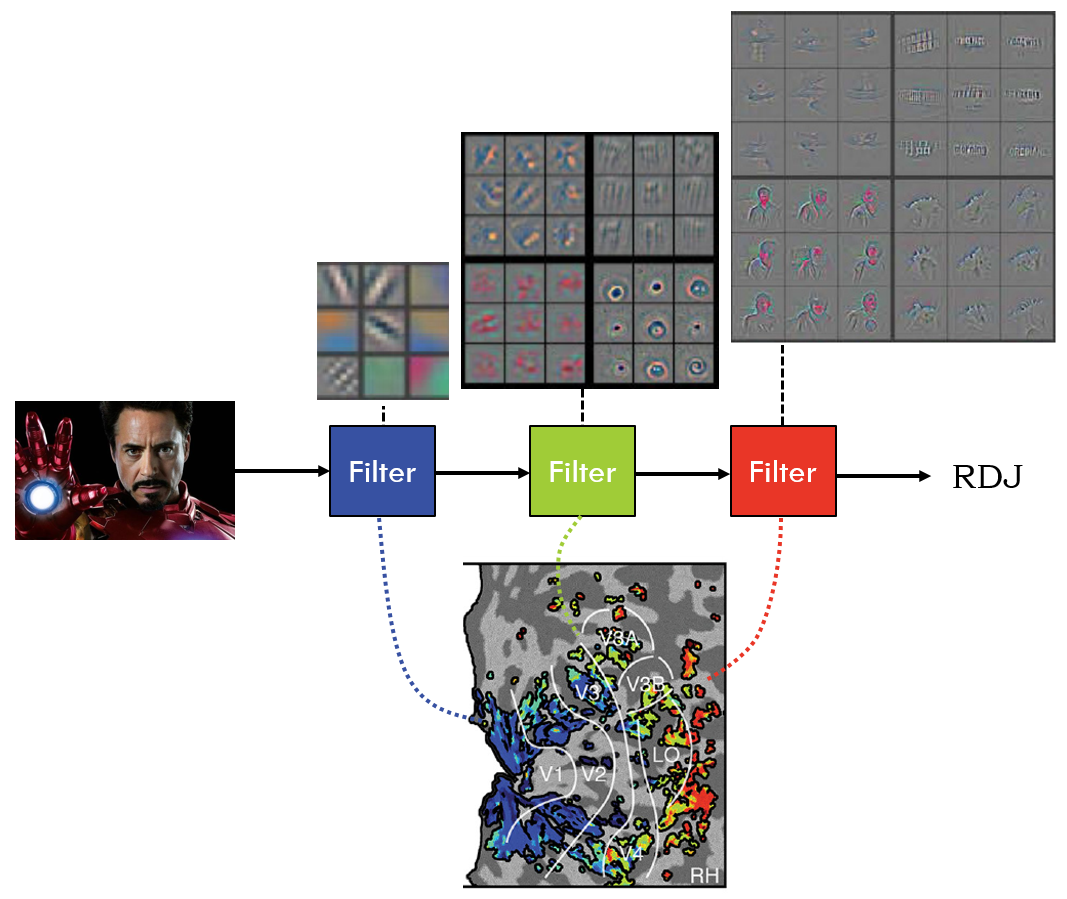 Zeiler & Fergus 2014, Güçlü & van Gerven 2015
Zeiler & Fergus 2014, Güçlü & van Gerven 2015
It seemed like things were mostly making sense, until two recent developments:
- The best-performing networks started requiring a lot of filters. For example, one of the current state-of-the-art networks uses 1,001 layers. Although we don’t know exactly how many layers the brain’s visual system has, it is almost certainly less than 100.
- These networks actually don’t get that much worse if you randomly remove layers from the middle of the chain. This makes very little sense if you think that each filter is combining shapes from the previous filter - it’s like saying that you can skip one step of a recipe and things will still work out fine.
Should we just throw up our hands and say that these networks just have way more layers than the brain (they’re “deeper”) and we can’t understand how they work? Liao and Poggio have a recent preprint that proposes a possible solution to both of these issues: maybe the later layers are all doing the same operation over and over, so that the filter chain looks like this:

Why would you want to repeat the same operation many times? Often it is a lot easier to figure out how to make a small step toward your goal and then repeat, instead of going directly to the goal. For example, imagine you want to set a microwave for twelve minutes, but all the buttons are unlabeled and in random positions. Typing 1-2-0-0-GO is going to take a lot of trial and error, and if you mess up in the middle you have to start from scratch. But if you’re able to find the “add 30 seconds” button, you can just hit it 24 times and you’ll be set. This also shows why skipping a step isn’t a big deal - if you hit the button 23 times instead, it shouldn’t cause major issues.
But if the last layers are just the same filter over and over, we can actually just replace them with a single filter in a loop, that takes its output and feeds it back into its input. This will act like a deep network, except that the extra layers are occurring in time:

So Liao and Poggio’s hypothesis is that very deep neural networks are like a brain that is moderately deep in both space and time. The true depth of the brain is hidden, since even though it doesn’t have a huge number of regions it gets to run these regions in loops over time. Their paper has some experiments to show that this is plausible, but it will take some careful comparisons with neuroscience data to say if they are correct.
Of course, it seems inevitable that at some point in the near future we will in fact start building neural networks that are “deeper” than the brain, in one way or another. Even if we don’t discover new models that can learn better than a brain can, computers have lots of unfair advantages - they’re not limited to a 1500 cm3 skull, they have direct access to the internet, they can instantly teach each other things they’ve learned, and they never get bored. Once we have a neural network that is similar in complexity to the human brain but can run on computer hardware, its capabilities might be advanced enough to design an even more intelligent machine on its own, and so on: maybe the “first ultraintelligent machine is the last invention that man need ever make.” (Vernor Vinge)
Comments? Complaints? Contact me
@ChrisBaldassano
20 May 2016
We usually think that our eyes work like a camera, giving us a sharp, colorful picture of the world all the way from left to right and top to bottom. But we actually only get this kind of detail in a tiny window right where our eyes are pointed. If you hold your thumb out at arm’s length, the width of your thumbnail is about the size of your most precise central (also called “foveal”) vision. Outside of that narrow spotlight, both color perception and sharpness drop off rapidly - doing high-precision tasks like reading a word is almost impossible unless you’re looking right at it.
The rest of your visual field is your “peripheral” vision, which has only imprecise information about shape, location, and color. Out here in the corner of your eye you can’t be sure of much, which is used as a constant source of fear and uncertainty in horror movies and the occult:
What’s that in the mirror, or the corner of your eye?
What’s that footstep following, but never passing by?
Perhaps they’re all just waiting, perhaps when we’re all dead,
Out they’ll come a-slithering from underneath the bed….
Doctor Who “Listen”
What does this peripheral information get used for during visual processing? It was shown over a decade ago (by one of my current mentors, Uri Hasson) that flashing pictures in your central and peripheral vision activate different brain regions. The hypothesis is that peripheral information gets used for tasks like determining where you are, learning the layout of the room around you, and planning where to look next. But this experimental setup is pretty unrealistic. In real life we have related information coming into both central and peripheral vision at the same time, which is constantly changing and depends on where we decide to look. Can we track how visual information flows through the brain during natural viewing?
Today a new paper from me and my PhD advisors (Fei-Fei Li and Diane Beck) is out in the Journal of Vision: Pinpointing the peripheral bias in neural scene-processing networks during natural viewing (open access). I looked at fMRI data (collected and shared generously by Mike Arcaro,Sabine Kastner, Janice Chen, and Asieh Zadbood) while people were watching clips from movies and TV shows. They were free to move their eyes around and watch as you normally would, except that they were inside a huge superconducting magnet rather than on the couch (and had less popcorn). We can disentangle central and peripheral information by tracking how these streams flow out of their initial processing centers in visual cortex to regions performing more complicated functions like object recognition and navigation.
We can make maps that show where foveal information ends up (colored orange/red) and where peripheral information ends up (colored blue/purple). I’m showing this on an “inflated” brain surface where we’ve smoothed out all the wrinkles to make it easier to look at:
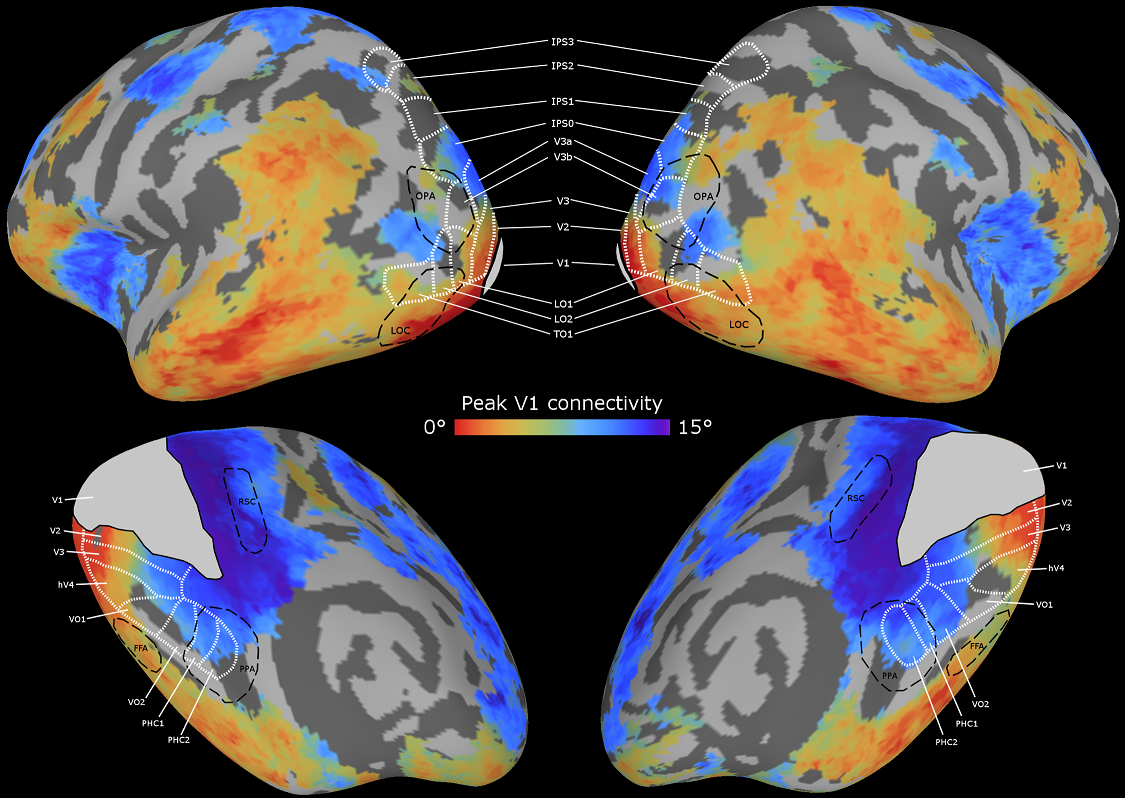
This roughly matches what we had previously seen with the simpler experiments: central information heads to regions for recognizing objects, letters, and faces, while peripheral information gets used by areas that process environments and big landmarks. But it also reveals some finer structure we didn’t know about before. Some scene processing regions care more about the “near” periphery just outside the fovea and still have access to relatively high-resolution information, while others draw information from the “far” periphery that only provides coarse information about your current location. There are also detectable foveal vs. peripheral differences in the frontal lobe of the brain, which is pretty surprising, since this part of the brain is supposed to be performing abstract reasoning and planning that shouldn’t be all that related to where the information is coming from.
This paper was my first foray into the fun world of movie-watching data, which I’ve become obsessed with during my postdoc. Contrary to the what everyone’s parents told them, watching TV doesn’t turn off your brain - you use almost every part of your brain to understand and follow along with the story, and answering questions about videos is such a challenging problem that even the latest computer AIs are pretty terrible at it (though some of my former labmates have started making them better). We’re finding that movies drive much stronger and more complex activity patterns compared to the usual paradigm of flashing individual images, and we’re starting to answer questions raised by cognitive scientists in the 1970s about how complicated situations are understood and remembered - stay tuned!
Comments? Complaints? Contact me
@ChrisBaldassano
